sebastiandaschner blog
Zero-Downtime Rolling Updates With Kubernetes
monday, october 15, 2018The software world moves faster than ever. In order to stay competitive, new software versions need to be rolled out as soon as possible, without disrupting active users. Many enterprises have moved their workloads to Kubernetes, which has been built with production-readiness in mind. However, in order to achieve real zero-downtime with Kubernetes, without breaking or loosing a single in-flight request, we need to take a few more steps.
This is the first part of a two-article series on how to achieve (real) zero-downtime with both Kubernetes ingress and Istio gateway resources. This part covers plain Kubernetes.
Rolling Updates
Per default, Kubernetes deployments roll-out pod version updates with a rolling update strategy. This strategy aims to prevent application downtime by keeping at least some instances up-and-running at any point in time while performing the updates. Old pods are only shutdown after new pods of the new deployment version have started-up and became ready to handle traffic.
Engineers can further specify the exact way how Kubernetes juggles multiple replicas during the update.
Depending on the workload and available compute resources we might want to configure, how many instances we want to over- or under-provision at any time.
For example, given three desired replicas, should we create three new pods immediately and wait for all of them to start up, should we terminate all old pods except one, or do the transition one-by-one?
The following code snippets shows the Kubernetes deployment definition for a coffee shop application with the default RollingUpdate upgrade strategy, and a maximum of one over-provisioned pods (maxSurge) and no unavailable pods during updates.
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: coffee-shop
spec:
replicas: 3
template:
# with image docker.example.com/coffee-shop:1
# ...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0The coffee-shop deployment will cause the creation of three replicas of the coffee-shop:1 image.
This deployment configuration will perform version updates in the following way: It will create one pod with the new version at a time, wait for the pod to start-up and become ready, trigger the termination of one of the old pods, and continue with the next new pod until all replicas have been transitioned. In order to tell Kubernetes when our pods are running and ready to handle traffic we need to configure liveness and readiness probes.
The following show the output of kubectl get pods and the old and new pods over time:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 3m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 3m
zero-downtime-5444dd6d45-fa1bc 1/1 Running 0 3m
...
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 3m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 3m
zero-downtime-5444dd6d45-fa1bc 1/1 Running 0 3m
zero-downtime-8dca50f432-bd431 0/1 ContainerCreating 0 12s
...
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 4m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 4m
zero-downtime-5444dd6d45-fa1bc 0/1 Terminating 0 4m
zero-downtime-8dca50f432-bd431 1/1 Running 0 1m
...
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 5m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 5m
zero-downtime-8dca50f432-bd431 1/1 Running 0 1m
zero-downtime-8dca50f432-ce9f1 0/1 ContainerCreating 0 10s
...
...
zero-downtime-8dca50f432-bd431 1/1 Running 0 2m
zero-downtime-8dca50f432-ce9f1 1/1 Running 0 1m
zero-downtime-8dca50f432-491fa 1/1 Running 0 30sDetecting Availability Gaps
If we perform the rolling update from an old to a new version, and follow the output which pods are alive and ready, the behavior first of all seems valid. However, as we might see, the switch from an old to a new version is not always perfectly smooth, that is, the application might loose some of the clients' requests.
In order to test, whether in-flight requests are lost, especially those made against an instance that is being taken out of service, we can use load test tools that connect against our application. The main point that we’re interested in is whether all HTTP requests are handled properly, including HTTP keep-alive connections. For that purpose we use a load testing tool, for example Apache Bench or Fortio.
We connect to our running application via HTTP in a concurrent fashion, using multiple threads, that is multiple connections. Instead of paying attention to the latency or throughput, we’re interested in the response statuses and potential connection failures.
In the example of Fortio, an invocation with 500 requests per second and 50 concurrent keep-alive connections looks as follows:
$ fortio load -a -c 8 -qps 500 -t 60s "http://coffee.example.com/.../coffees"
The -a option causes Fortio to save the report so that we can view it using the HTML GUI.
If we fire up this test while a rolling update deployment is happening, we will likely see that a few requests fail to connect:
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20s
Starting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)
08:49:55 W http_client.go:673> Parsed non ok code 502 (HTTP/1.1 502)
[...]
Code 200 : 9933 (99.3 %)
Code 502 : 67 (0.7 %)
Response Header Sizes : count 10000 avg 158.469 +/- 13.03 min 0 max 160 sum 1584692
Response Body/Total Sizes : count 10000 avg 169.786 +/- 12.1 min 161 max 314 sum 1697861
[...]The output indicates that not all of the requests could be handled successfully. We can run several test scenarios that connect to the application through different ways, e.g. via Kubernetes ingress, or via the service directly, from inside the cluster. We’ll see that the behavior during the rolling update might vary, depending on how our test setup connects. Clients that connect to the service from inside the cluster might not experience as many failed connections compared to connecting through an ingress.
Understanding What Happens
Now the question is, what exactly happens when Kubernetes re-routes the traffic during the rolling update, from an old to a new pod instance version. Let’s have a look how Kubernetes manages the workload connections.
If our client, that is the zero-downtime test, connects to the coffee-shop service directly from inside the cluster, it typically uses the service VIP resolved via Cluster DNS and ends up at a Pod instance.
This is realized via the kube-proxy that runs on every Kubernetes node and updates iptables that route to the IP addresses of the pods.
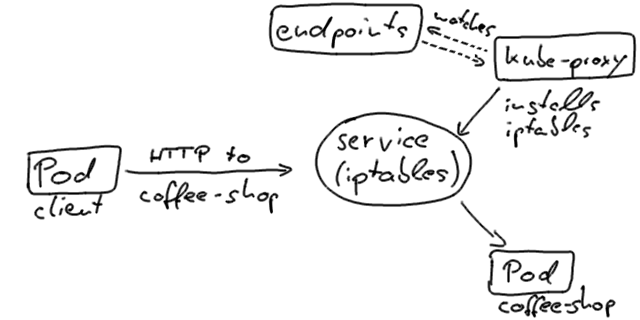
Kubernetes will update the endpoints objects in the pods states so that it only contains pods that are ready to handle traffic.
Kubernetes ingresses, however, connect to the instances in a slightly different way. That’s the reason why you will notice different downtime behavior on rolling updates, when your client connects to the application through an ingress resource, instead.
The NGINX ingress directly includes the pod addresses in its upstream configuration. It independently watches the endpoints objects for changes.
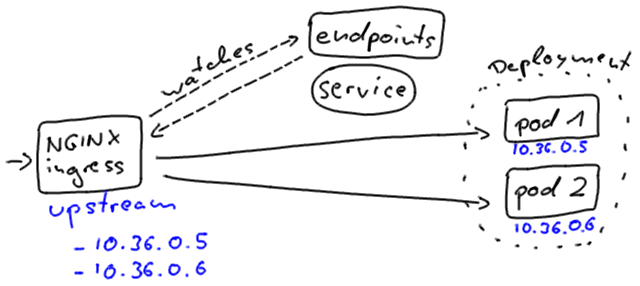
Regardless of how we connect to our application, Kubernetes aims to minimize the service disruption during a rolling update process.
Once a new pod is alive and ready, Kubernetes will take an old one out of service and thus update the pod’s status to Terminating, remove it from the endpoints object, and send a SIGTERM.
The SIGTERM causes the container to shutdown, in a (hopefully) graceful manner, and to not accept any new connections.
After the pod has been evicted from the endpoints object, the load balancers will route the traffic to the remaining (new) ones.
This is what causes our availability gap in our deployment; the pod is being deactivated by the termination signal, before, or rather while the load balancer notices the change and can update it’s configuration.
This re-configuration happens asynchronously, thus makes no guarantees of correct ordering, and can and will result in few unlucky requests being routed to the terminating pod.
Towards Zero-Downtime
How to enhance our applications to realize (real) zero-downtime migrations?
First of all, a prerequisite to achieve this goal is that our containers handle termination signals correctly, that is that the process will gracefully shutdown on the Unix SIGTERM.
Have a look at Google’s best practices for building containers how to achieve that.
All major Java Enterprise application servers handle termination signals; it’s up to us developers that we dockerize them correctly.
The next step is to include readiness probes that check whether our application is ready to handle traffic. Ideally, the probes already check for the status of functionality that requires warm-ups, such as caches or servlet initialization.
The readiness probes are our starting point for smoothing the rolling updates.
In order to address the issue that the pod terminations currently does not block and wait until the load balancers have been reconfigured, we’ll include a preStop lifecycle hook.
This hook is called before the container terminates.
The lifecycle hook is synchronous, thus must complete before the final termination signal is being sent to the container.
In our case, we use this hook to simply wait, before the SIGTERM will terminate the application process.
Meanwhile, Kubernetes will remove the pod from the endpoints object and therefore the pod will be excluded from our load balancers.
Our lifecycle hook wait time ensures that the load balancers are re-configured before the application process halts.
To implement this behavior, we define a preStop hook in our coffee-shop deployment:
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: coffee-shop
spec:
replicas: 3
template:
spec:
containers:
- name: zero-downtime
image: docker.example.com/coffee-shop:1
livenessProbe:
# ...
readinessProbe:
# ...
lifecycle:
preStop:
exec:
command: ["/bin/bash", "-c", "sleep 20"]
strategy:
# ...It highly depends on your technology of choice how to implement the readiness and liveness probes as well as the lifecycle hook behavior; the latter chooses a 20 seconds synchronous grace period. The the pod shutdown process only continues after this wait time.
Note: A previous version of this article also included a script to deactivate the readiness probe. As Marko Lukša thankfully pointed out, this behavior is not necessary since the Endpoint controller will remove the pod from the endpoints object, anyway.
In the case of Java Enterprise we’d typically implement the probes as HTTP resources, using JAX-RS or MicroProfile Health, for example. The lifecycle hook would need to deactivate the health check resource via another method, or some container-internal shared resources.
When we now watch the behavior of our pods during a deployment, we’ll see that the terminating pod will be in status Terminating but not be shutdown before the wait time period ends.
If we re-test our approach using Fortio, we’ll see the desired behavior of zero failed requests:
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20s
Starting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)
[...]
Code 200 : 10000 (100.0 %)
Response Header Sizes : count 10000 avg 159.530 +/- 0.706 min 154 max 160 sum 1595305
Response Body/Total Sizes : count 10000 avg 168.852 +/- 2.52 min 161 max 171 sum 1688525
[...]Conclusion
Kubernetes does an excellent job in orchestrating applications with production-readiness in mind. In order to operate our enterprise systems in production, however, it’s key that we engineers are aware of both how Kubernetes operates under the hood and how our applications behave during startup and shutdown.
In the second part of the article series we’ll see how to achieve the same goal of zero-downtime updates when we run Istio on top of Kubernetes. We’ll also discover how to combine these approaches with Continuous Delivery environments.
Further Resources
- Example GitHub project (Kubernetes ingress version)
- Services — Kubernetes documentation
- Termination of Pods — Kubernetes documentation
- Zero Downtime Deployments in Kubernetes by Chris Moos — Thanks to the author for inspiring these articles
- Best Practices for Building Containers — Google Cloud
- Handling Client Requests Properly with Kubernetes by Marko Lukša
Update 2018-10-18: Changed preStop lifecycle handler to only sleep and not deactivate the readiness probe.
For more information, see this article.
Thanks to Marko Lukša for pointing this out.
Found the post useful? Subscribe to my newsletter for more free content, tips and tricks on IT & Java: