sebastiandaschner blog
Zero-Downtime Rolling Updates With Istio
thursday, october 18, 2018The first part of this article series explained how to achieve real zero-downtime updates in Kubernetes clusters. We specifically tackled request failures that arise when switching traffic from old to new instances. This article will show how to achieve the same goal using Istio clusters.
Service mesh technology, such as Istio, is often used in combination with container orchestration. Istio provides cross-cutting concerns such as resiliency, telemetry, and advanced traffic management to our applications, in a transparent fashion.
When we’re using Istio, the cluster-internal networking model looks a bit differently compared to plain Kubernetes. You can have a look at the following explanation video if you’re unfamiliar with how Istio’s current networking API is designed.
Attempting Zero-Downtime With Istio
Let’s start from where the first part of the article left off.
If we take our application and re-deploy it to an Istio cluster in a similar way as before, we will notice that the behavior during updates differs.
When we re-run the load tests that aim to detect availability gaps, we will notice that despite our preStop pod lifecycle handlers, there are some failed requests.
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20s
Starting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)
09:11:39 W http_client.go:673> Parsed non ok code 503 (HTTP/1.1 503)
[...]
Code 200 : 9960 (99.6 %)
Code 503 : 40 (0.4 %)
Response Header Sizes : count 10000 avg 165.204 +/- 10.43 min 0 max 167 sum 1652048
Response Body/Total Sizes : count 10000 avg 176.12 +/- 3.817 min 171 max 227 sum 1761200
[...]As the output indicates there are some HTTP requests that failed with a 503 Service Unavailable status code.
No matter how we tweak the wait time of our preStop handler, we seem to loose at least a few client requests, when updating our service during high traffic.
Similarly, there seems to be little difference in whether we access an Istio service from within the mesh, or from outside the cluster, through a gateway.
Understanding What Happens
To understand what happens, let’s have a closer look how the Istio sidecar containers connect to individual services.
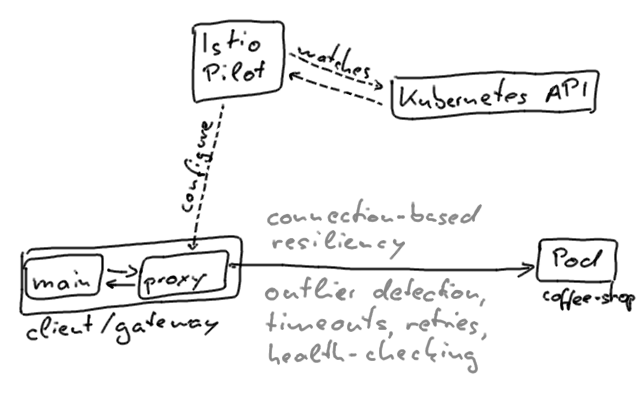
All traffic within the mesh is routed through the sidecar proxies that connect to the individual instances. The same is true for ingress traffic that goes through a gateway.
In our scenario this means that the sidecars might not connect to the instances, even though they’re supposedly ready to serve traffic. The proxies are configured in an eventually consistent manner; the configuration changes from the Pilot plane propagate gradually.
Envoy also performs active health checking of instances, it will detect outliers and ultimately prevent connections to them. HTTP-based readiness probes that are defined for pods will also be included and executed by the Envoy proxies. In other words, the proxy containers won’t connect to pods whose readiness probes fail, even if the pods would still accept requests. Retry configuration which we can add to the sidecar proxies through the mesh configuration only mitigates but doesn’t resolve this issue.
Towards Zero-Downtime With Istio
There are approaches to introduce more enhanced health-checking concepts to Kubernetes in the future.
However, currently, a reasonable balance between effort and reliability is to use Istio subsets as version designators and to re-route the service traffic independent of Kubernetes' rolling update mechanism.
With that approach, we use a service subset to identify the application’s version, such as v1 or v2, and configure the virtual service to route to one specific version.
The Istio proxies routes which are configured by the virtual service resources can be re-routed to different subset versions with real zero-downtime.
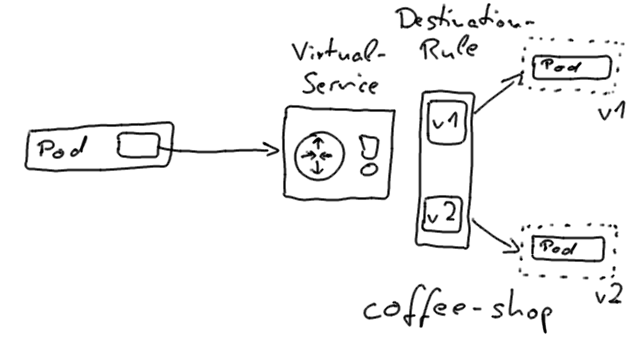
In order to use that approach, we’ll create separate Kubernetes deployments, one for each individual version of our application, and perform the actual switch via Istio.
An example deployment looks as follows:
-
Initially: Kubernetes deployment
coffee-shop-v1with labelsapp=coffee-shop,version=v1, destination rule that defines subsetv1, and virtual service that routes tocoffee-shopv1 -
We enhance the destination rule to include a new subset for version
v2 -
We create a deployment
coffee-shop-v2withversion=v2 -
After the deployment has been successfully rolled out, we reroute the virtual service to
v2. The switch will happen without a lost request. -
After a short waiting period, we remove the subset
v1from the destination rule, and the deploymentcoffee-shop-v1
If we re-run the same load test from the first part, we’ll notice that we can perform an actual zero-downtime deployment.
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20s
Starting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)
[...]
Code 200 : 10000 (100.0 %)
Response Header Sizes : count 10000 avg 159.530 +/- 0.706 min 154 max 160 sum 1595305
Response Body/Total Sizes : count 10000 avg 167.853 +/- 2.51 min 161 max 171 sum 1678534
[...]You can have a look at the explanation video if you’re unfamiliar with how you would implement this process using Istio’s networking API.
Automation Is Key
Of course, we don’t want to perform these steps manually. The idea is to define an automated process that is performed on every new software version. Ultimately, this deployment should happen as part of a Continuous Delivery pipeline which deploys our software to the corresponding environments.
We can enhance our Continuous Delivery pipeline to deploy canary releases where we only route a small percentage of the user traffic to. This would be equally included into the pipeline as automated approach: gradually routing the user traffic to a newly deployed version and then performing a full switch once the canary version has proven itself to work well.
It helps if we define our deployment and Istio routing definitions in a templating language. By doing so we can reliably define and change the application versions and image versions and roll-out the changes consistently. The coffee-shop example project includes an automation script that performs a zero-downtime deployments with Istio and that builds upon a YAML templating approach using kontemplate.
Conclusion
Kubernetes' production-readiness is a valuable feature which is included out-of-the-box. However, we need to take more into consideration, to fully realize zero-downtime behavior. It’s crucial to test the downtime of the application that you’ll be running in production and adjust the probes and various timeouts accordingly.
It certainly helps to know how Kubernetes and Istio manage the connections to the backend, respectively. If we tweak the behavior during updates slightly, we can iron out the last availability gaps.
Zero-downtime with correct connection draining and keep-alive connection handling enables our applications to be deployed anytime, without disrupting their users. Once we are at this point, we can continuously improve our software and ship features and bug fixes to production faster. Therefore, zero-downtime deployments are one of the prerequisites of a functioning Continuous Delivery and Continuous Improvement culture.
- Example GitHub project (Istio version)
- Zero-Downtime Rolling Updates With Kubernetes (first part)
- Istio Networking API explanation video
- Kontemplate (Kubernetes templating tool)
Found the post useful? Subscribe to my newsletter for more free content, tips and tricks on IT & Java: