sebastiandaschner blog
Efficient enterprise testing — integration tests (3/6)
thursday, september 26, 2019This part of the series will show how to verify our applications with code-level as well as system-level integration tests.
(Code-level) integration tests
The term integration test is sometimes used differently in different contexts. What I’m referring to, following the Wikipedia definition, are tests that verify the interaction of multiple components, here on a code level. Typically, integration tests make use of embedded containers or other simulated environments in order to test a subset of the application. Test technology such as Spring Tests, Arquillian, CDI-Unit, and others make it easy to write tests and easy to inject individual classes into the test class for direct interaction during the test execution.
The following shows a pseudo code example of an integration test that uses a CDI-Unit runner:
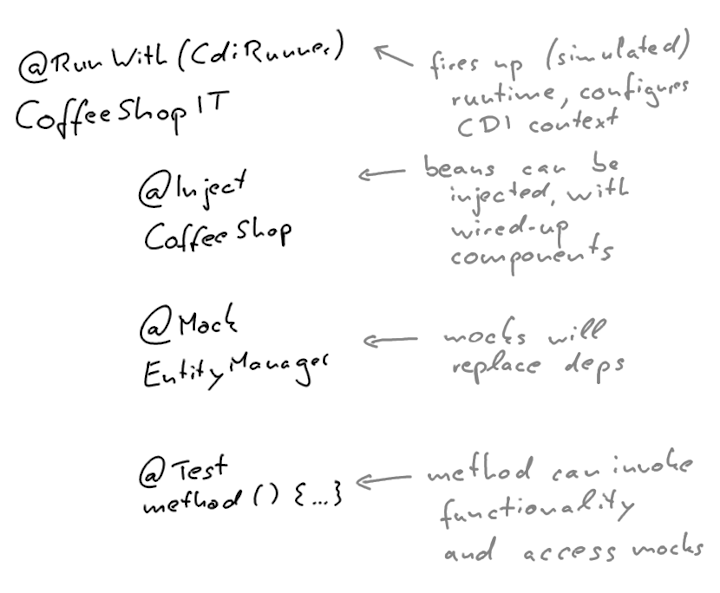
The test scenario can easily inject and mock dependencies and access them within the test methods.
Since the embedded test technology takes a few moments to start up, embedded integration tests usually have the biggest negative impact in overall test execution time. From my experience, a lot of projects copy-and-paste existing test scenarios and run them in a way where every test class will start up the application, or parts of it, all over again. Over time, this increases the turnaround time of the build so much, that developers won’t get a fast feedback.
While these type of tests can verify the correctness of the “plumbing”, whether the APIs and annotation have been used correctly, they are not the most efficient way to test business logic. Especially in microservice applications, integration tests don’t provide ultimate confidence, whether the integration especially of endpoints and persistence will behaves exactly like it does in production. Ultimately, there can always be tiny differences in the way how JSON objects are being mapped, HTTP requests are being handled, or objects are persisted to the datastore.
The question is always, what our tests should really verify. Are we verifying the framework and it’s correct usage or the correct behavior of our overall application?
Code-level integration tests work well for a fast feedback whether developers made some careless mistakes in wiring up the frameworks. A few single test cases that in this case don’t verify the business logic but just the application is able to start up, in a smoke test fashion, can increase the development efficiency.
However, if our applications don’t make use of our enterprise framework in an overly complex way, for example using custom qualifiers, CDI extensions, or custom scopes, the need for code-level integration tests decreases. Since we have ways to catch the same types of errors, and many others, using system tests, I usually discourage developers from writing too many code-level integration tests. Integration tests indeed make it easy to wire-up multiple components on a code level, however, it’s possible to use different approaches, like use case tests, which don’t come with the startup time penalty.
Since integration test technologies usually start up or deploy to an container, they usually define their own life cycle and make it harder to be integrated into a bigger picture. If developers want to craft an optimized development workflow, by running the application in a mode that hot-reloads on changes in a different life cycle and then quickly execute integrative tests against the running application, this is not easily possible by these type of integration tests, since they would usually start their own application. There are some technologies out there that improve this, for example Quarkus and its integration tests. Still, an easier and more flexible way is to keep the test scenarios separate from the life cycle of the overall application context.
Tangling tests with the life cycle of (embedded) applications also makes it harder to reuse test scenarios for multiple scopes, since they usually require to be executed with specific runners or further constraints. We’ve had many cases where reusing the test scenarios, the code that defines the logical part of the test, in different scopes simplified enhancing the test suite, for example for use case tests, load tests, or system tests. If the cases don’t put too many constraints on how they have to be executed, for example with which test runner, reusing them, i.e. copying them some place else and swapping the implementation of used delegates or components, becomes much simpler. As you will see in the following, there are more effective ways how to fully verify our applications, especially for more complex projects.
System tests
In a microservice world, our applications integrate more and more with other resources such as external systems, databases, queues, or message brokers, and typically include less extremely complex business logic. That being said, it is crucial to verify the behavior of our systems from an outside perspective, that is, interacting with our applications in the same way as the other components will in production.
System tests verify the behavior of deployed applications by making use of the regular interfaces, for example HTTP, gRPC, JMS, or WebSockets. They are executed against an environment, where the application-under-test is deployed and configured exactly like in production, with external systems usually being mocked or simulated. Test scenarios can interact with the mocked external systems to further control the scenario and verify the behavior. Container technologies, mock servers, and embedded databases can help a lot in this regard.
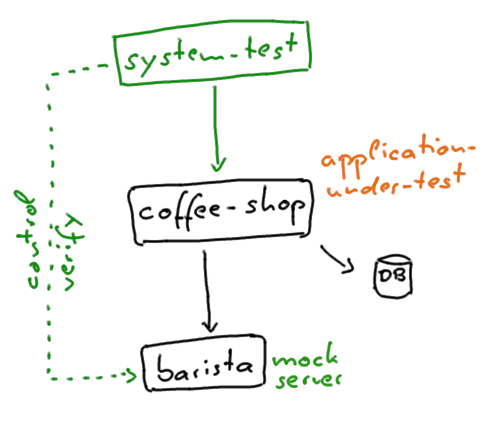
In general, system tests can be written in all kinds of various technology, since they are decoupled from the implementation. It usually makes sense though to use the same technology as in the application project, since the developers are already familiar with it, e.g. also using JUnit with HTTP clients such as JAX-RS.
We should be careful not to couple the system tests with the actual implementations, that is, not to re-use class definitions or import shared modules. While this is tempting in project to reduce duplication, it actually increases the likelihood to miss regression when application interfaces change, sometimes per accident. If, for example, both the production code and test code changes the way how objects are serialized to JSON, this potentially unwanted change in the API contract won’t be caught if the class definitions are being reused (i.e. “garbage in, garbage out”). For this reason, it’s usually advisable to keep the system tests in separate projects, that use their own, potentially simplified class definitions, or to enforce in other ways that the test classes won’t re-use production code. The implementation should indeed verify that the communication happens as expected, e.g. check for expected HTTP status code. If there is an unwanted change in the production behavior, the system test project and its behavior hasn’t been modified and will detect the change in the contract.
Since system test scenarios can quickly become fairly complex, we need to care about maintainability and test code quality. We’ll have a closer look at this in a second, but in general, it’s advisable to construct special delegates for controlling and communicating with the mocked external systems, as well as for creating test data.
What else becomes crucial for more complex setups is to define idempotent system tests that verify a specific behavior regardless of the current state. We should avoid creating test scenarios that only work against a fresh, empty system or need to be executed in a specific order. Real-world business uses cases are usually also performed on longer-running systems and executed simultaneously. If we achieve the same grade of isolation in our system tests, we avoid that the tests are tangled to specific preconditions or the order of execution, and we can run them in parallel, or against a local development environment that can keep running for more than one test run. This is a prerequisite for both setting up effective local workflows as well as to potentially reuse the test scenario definitions for different purposes.
In order to keep environments similar, the question is how production looks like and how we can come as close as possible during local development or in Continuous Delivery pipelines. In general, the advent of containers made it much simpler to achieve that goal. If our applications run in containers we have multiple ways to execute them locally, either starting them via shell scripts, Docker Compose, testcontainers, which we’ll have a look at in a second, or we even run a fully-fledged Kubernetes or OpenShift cluster. In Continuous Delivery pipelines we ideally deploy to and test against an environment in the same way as we do to production, a cluster or environment that uses the same technology and configuration, for example a separate Kubernetes cluster or namespace.
Depending on the complexity of the system and the local development workflow, we can manage the life cycle of the deployed application in the system test execution, or externally, via separate tools. From experience, managing the environment externally, that is starting it up via a separate mechanism and running the idempotent tests against it, is faster to execute, allows for more flexibility in our workflow, and is ultimately also easier to manage. A very convenient way for this is to define shell scripts that wrap the actual commands, such as how to start the Docker containers, setup Docker compose, start Kubernetes and apply the YAML files, or else, and then to simply execute the scripts at the beginning of the development session. The system tests then run very quickly since they have an independent life cycle and connect to an environment that is already running. This can be achieved for both dedicated test environments and local setups. Setting up complex environments locally sounds like a big turnaround for changing some behavior and verify our changes, however, modern development tools with hot-deployment techniques support us in keeping the cycles instantly fast. We can modify the behavior of the application-under-test instantly and re-execute the test cases, that also run very quickly.
This approach gives us a very fast feedback yet proper verification, since we’re testing against the actual application interfaces, not simulations. However, it’s crucial that we keep our setup maintainable in order to keep the complexity manageable.
In the next part of the article series we will cover effective development workflows and the importance of test code quality and how to achieve that our tests stay maintainable.
Found the post useful? Subscribe to my newsletter for more free content, tips and tricks on IT & Java: